💡 STACK과 QUEUE의 자료구조에 대해 설명하시오.
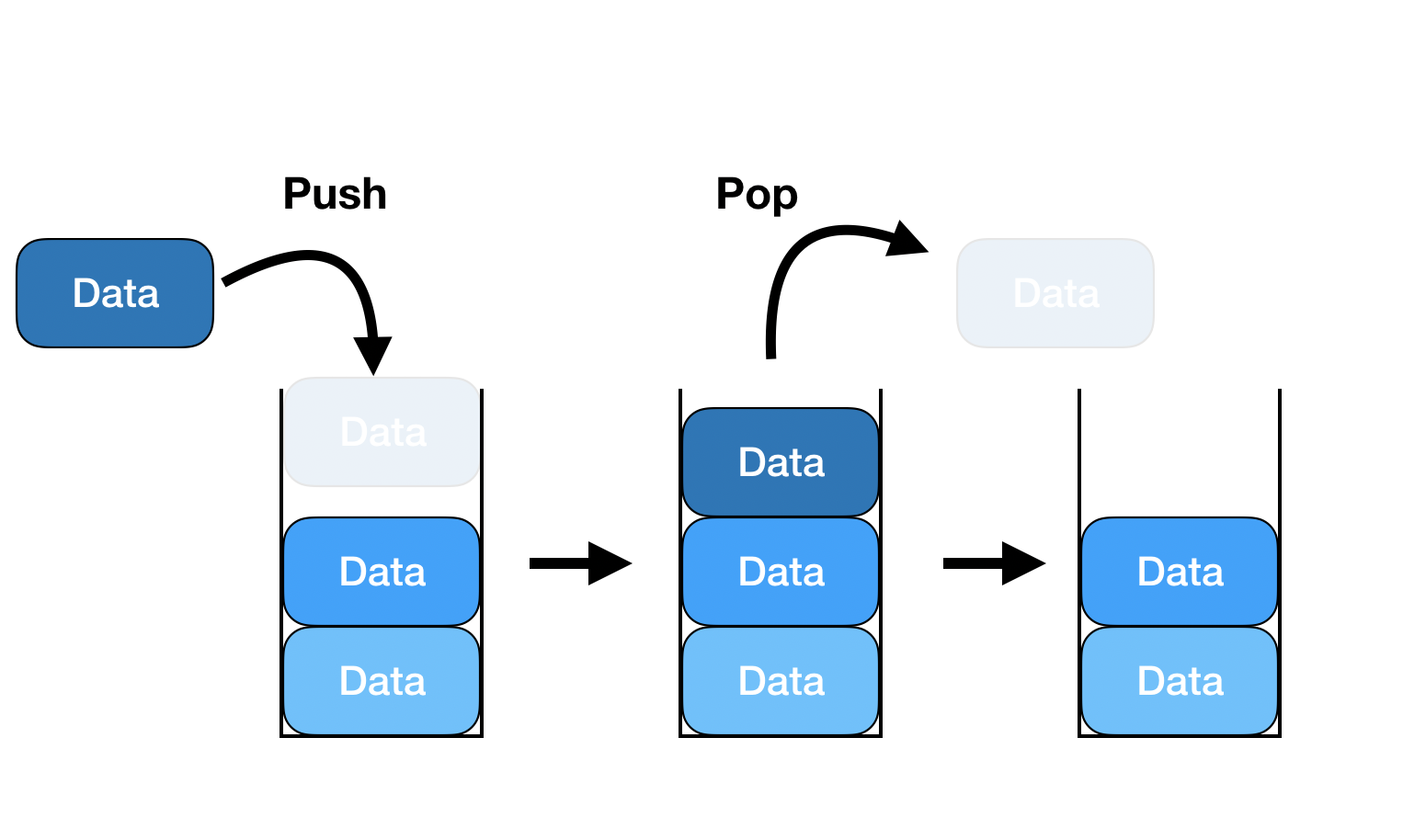
STACK 이란?
- 같은 구조와 크기의 자료를 TOP 방향으로만 쌓는 구조 => 위에 뚜껑 열린 구조
- 가장 최근에 삽입된 데이터가 가장 위에 쌓이고 가장 먼저 삭제 된다.
- LIFO (Last In First Out) 후입선출 구조
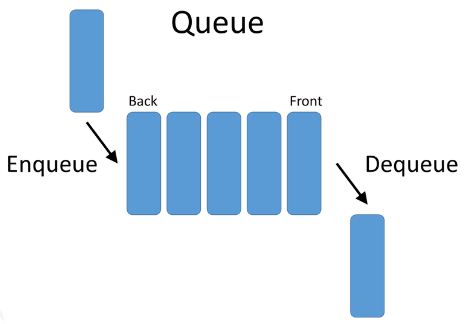
Queue
- 한 쪽은 삽입, 다른 한 쪽은 삭제를 담당하는 구조
- 삽입 연산이 이루어지는 REAR, 삭제 연산이 이루어지는 FRONT로 구성
- FIFO(First In First Out) 선입선출 구조
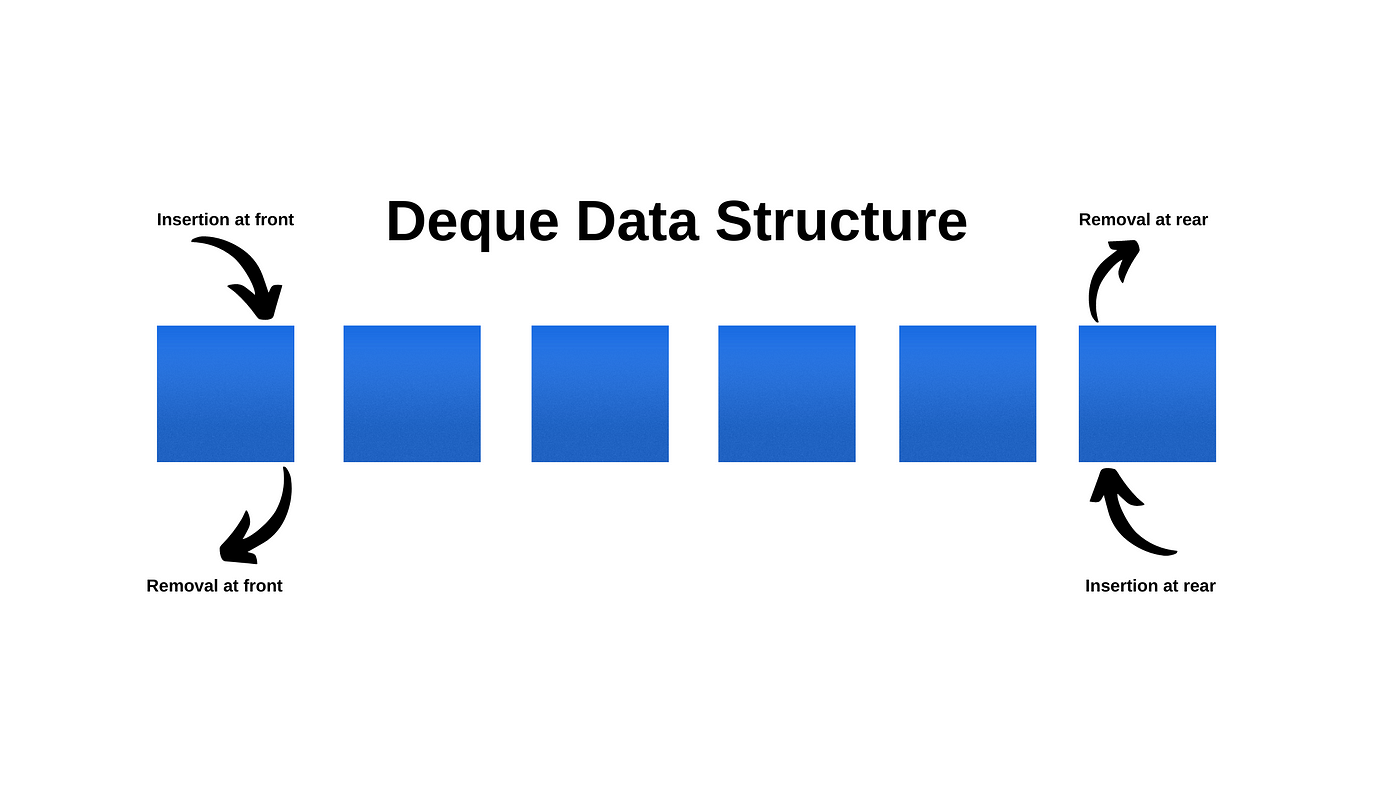
- 선형 큐 : 위 사진 처럼 front에 공간이 나면 밀어줘야 하는 구조
- 원형 큐 : front와 rear을 원형으로 회전시키는 개념
- 예시로 링버퍼가 있는데 오래된 자료는 삭제시키는 것이다.

- Deque 덱
- Double-ended queue의 줄임말로 전, 후단 삽입 삭제가 모두 가능하다.
💡 Array와 Liked List 자료구조와 차이
Array
- 특정 크기 만큼 모든 요소는 중간에 빈자리가 없이 반드시 메모리의 연속된 공간에 저장되어있어야 한다.
- 연속된 메모리로 구성되어 있기에 덧셈 한 번, 곱 셈 한 번이면 데이터 주소를 알아 데이터 조회가 금방 가능하다.
- 데이터를 추가하려면 한 자리를 비워야 하고 모든 자료가 한 칸씩 밀리게 되어 추가 된다. 삭제는 지양
- 데이터 추가 및 삭제 시 O(N) 소모
Linked List (연결 리스트)
- 메모리에 흩어져 있는 요소들을 링크로 연결해 하나로 관리
- 노드는 연속된 공간에 존재하지 않기에 데이터 조회시 처음부터 순차적으로 접근해야 한다.
- 메모리 관리가 용이하다
- 추가 및 삭제 O(1) 소모
1. 데이터의 주소 찾기는 Array가 빠르고, 데이터 추가 삭제는 Linked List가 빠르다.
2. 수정 시에는 동적으로 Linked List 크가 결정되어 Array에 비해 처음부터 큰 공간을 할당할 필요 없다. (메모리 낭비 x)
3. Array와 LinkedList는 Trade-Off 관계이다.
💡 RDB와 NoSQL은 무엇이고 차이점
RDB(Relational DataBase)
- 관계형 모델을 기반, 이를 관리하기 위한 시스템을 RDBMS(management system)이라 한다.
- 모든 데이터를 2차원의 테이블 형태로 표현
- 정해진 스키마에 따라 데이터를 저장하고 명확한 데이터 구조를 보장한다.
- 스키마로 인해 데이터가 유연하지 못하고, 스키마가 변경될 때 번거롭고 까다롭다.
- 외래키와 같은 관계가 설정되어 있어 결제 등의 복잡한 트랜잭션 처리에 강하다.
- 테이블 설계시 정규화를 통해 데이터 중복 저장을 없앰
- 테이블 간 Join 연산 가능
- 단점 : 테이블 간 관계를 맺고 있어서 시스템이 커질 경우 과도한 데이터 join으로 인해 시스템 과부하 걸릴 수 있음
NoSQL(Not only SQL)
- 비관계형으로 데이터를 저장하는 형태
- 명시된 제약이나 규칙이 없어 데이터 레이크(Data lake) 같은 빅데이터에 사용을 많이 한다.
- 연산이 빨라 빅데이터와 실시간 연산 등에 적합
- 데이터 분산이 용이, 성능 향상을 위한 scale-up, scale-out 가능
- key-value나 document로 저장하는 것이 일반적이다.
- 단점 : 데이터 중복 발생 가능이 RDB에 비하면 높다. 중복 데이터 변경 시 수정을 해당 모든 컬렉션에서 진행 해야 한다.
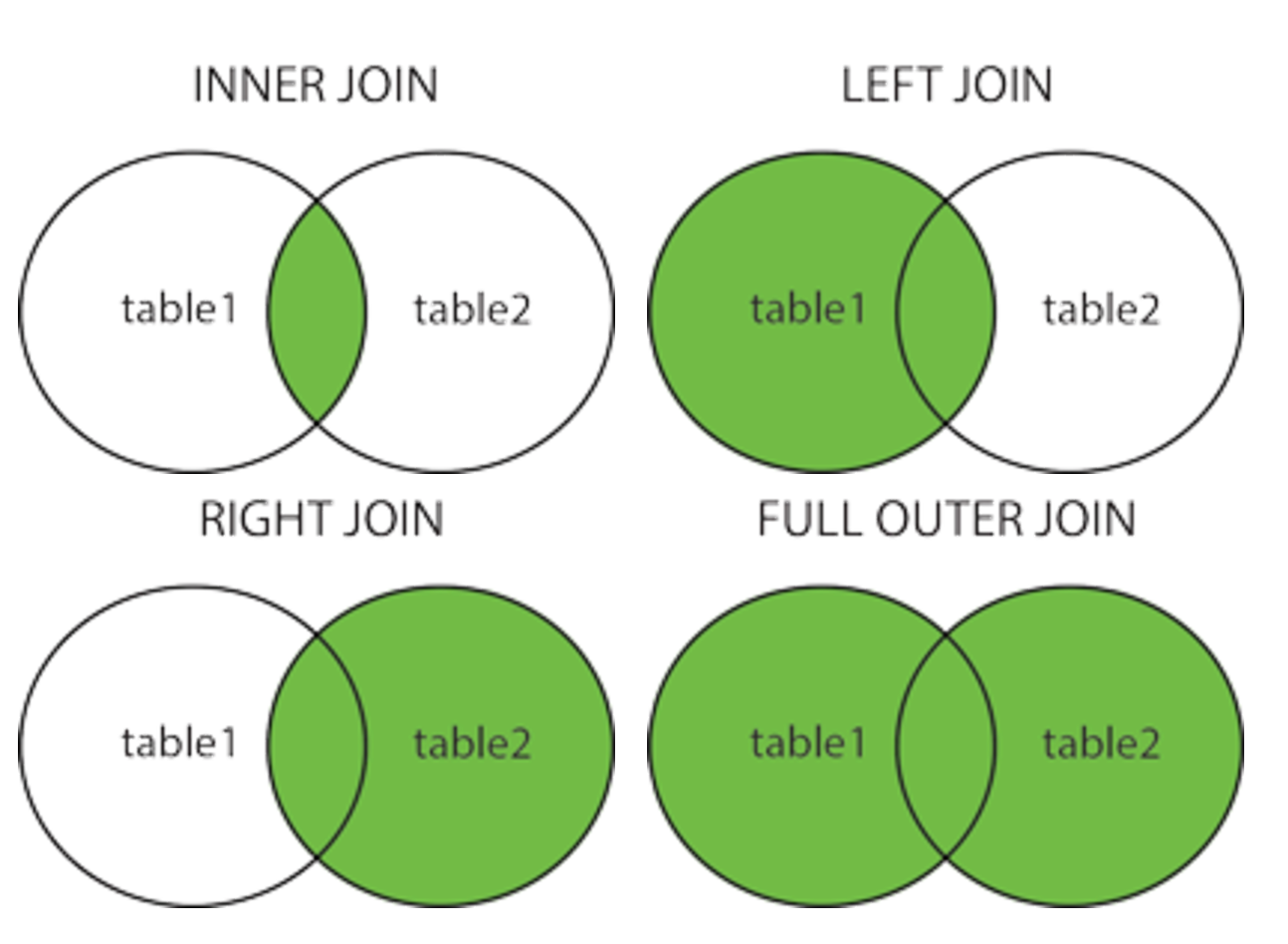
💡 Inner Join과 Left(Outer) Join에 차이점
Join : 두 개의 테이블끼리 관계를 맺어 원하는 데이터 조회
Inner Join
- 서로 연관된 내용만 검색하는 조인 방법 (교집합)
Outer Join
- 한 쪽에는 데이터가 있고 한 쪽에는 없는 경우, 데이터가 있는 쪽으로 전부 출력
💡 트랜잭션(Transaction)의 의미와 ACID 규칙에 대해 설명
트랜잭션
- DB 쿼리문에 의해 발생하는 일정 작업의 단위
- 작업의 완전성 보장
- 작업들을 모두 처리하지 못할 때에 이전 상태로 복구하여 작업의 일부만 적용되는 현상을 막음
- 하나의 트랜잭션은 Commit or Rollback 뿐
트랜잭션의 특성 ACID
- 원자성(Automicity) : 작업이 모두 반영되던지 아니면 전혀 반영되지 X
- 일관성(Consistency) : 실행이 완료되면 언제나 일관성 있는 상태를 유지
- 독립성(isolation) : 둘 이상 트랜잭션이 동시에 실행될 경우 서로의 연산에 끼어 들 수 없다.
- 영속성(Durability) : 완료된 결과는 영구적으로 반영
💡 Primary Key 와 Foriegn Key
Primary Key(기본키)
- 테이블 내의 각각의 데이터를 유일하게 구분하는 키
- 테이블 내의 하나의 pk만 허용 한다.
- NULL 값을 허용하지 않는다, 상위 테이블에서 삭제 X
Foriegn Key(외래키)
- 다른 테이블 PK를 참조
- NULL 가능, 상위 테이블에서 해당 값 삭제 가능
- 참조하는 데이터의 무결성을 높인다.
- 데이터의 무결성 : DB내 데이터가 정확하고 일관성 있게 유지
- 관계를 설정하여 참조된 테이블 데이터에 접근 가능